
Token 是系统资源:OpenClaw 的上下文管理架构设计

Token 是系统资源,而不是聊天记录
这是 OpenClaw 在设计长期运行 Agent 系统时,一个被反复验证过的结论。
在大多数 AI 产品中,Context Window 被当成“对话历史”。在 OpenClaw 中,它被当成和 RAM、CPU 同级的 稀缺系统资源。这两种理解,决定了系统能不能跑得久。
从物理约束开始,而不是从聊天开始
Context Window 不是抽象概念,而是明确的物理上限。
当上下文无限堆叠时,会发生三件确定的事情: - 有效指令被历史噪音淹没 - Token 成本和延迟快速失控 - Agent 偏离最初目标,在局部细节中打转
这不是模型问题,而是系统设计问题。
OpenClaw 的选择很直接:把 token 上升为一等系统资源,用系统方法去管理它。
为什么只靠参数规则一定会失败
行业里最常见的做法是参数化控制:TTL、滑动窗口、定期 summary。
这些方法工程上简单,但语义上是盲的: - TTL 会删除“依然重要但不再新鲜”的决策 - 机械总结会把关键约束和无关闲聊一起压缩
结果是:系统看似在“管理 token”,实际上在随机丢失上下文价值。
这也是 OpenClaw 不满足于单层参数策略的原因。
OpenClaw 的双层上下文架构
OpenClaw 将 token 管理明确拆成两层,各司其职。
第一层:安全兜底层(Safety Net)
这一层完全参数化,对 Agent 逻辑不可见,目标只有一个:
系统永远不要因为 token 耗尽而崩溃。
它负责: - token 使用监控 - 紧急压缩 - TTL 清理非活跃会话
第二层:语义生命周期层(Semantic Lifecycle)
这是 OpenClaw 的核心,也是“智能”发生的地方。
在这一层,token 的去留不由时间决定,而由项目与意图决定。
- 写作任务:只保留当前段落和结构,大段正文外移
- 架构设计:保留决策与约束,推理过程在结论确定后立即释放
- 日常对话:采用简单 FIFO,不引入额外复杂度
一句话原则:保留结果,释放过程。
从架构视角看 Token 管理栈
下面这张图,是 OpenClaw 对 token / context 管理的整体架构视图:
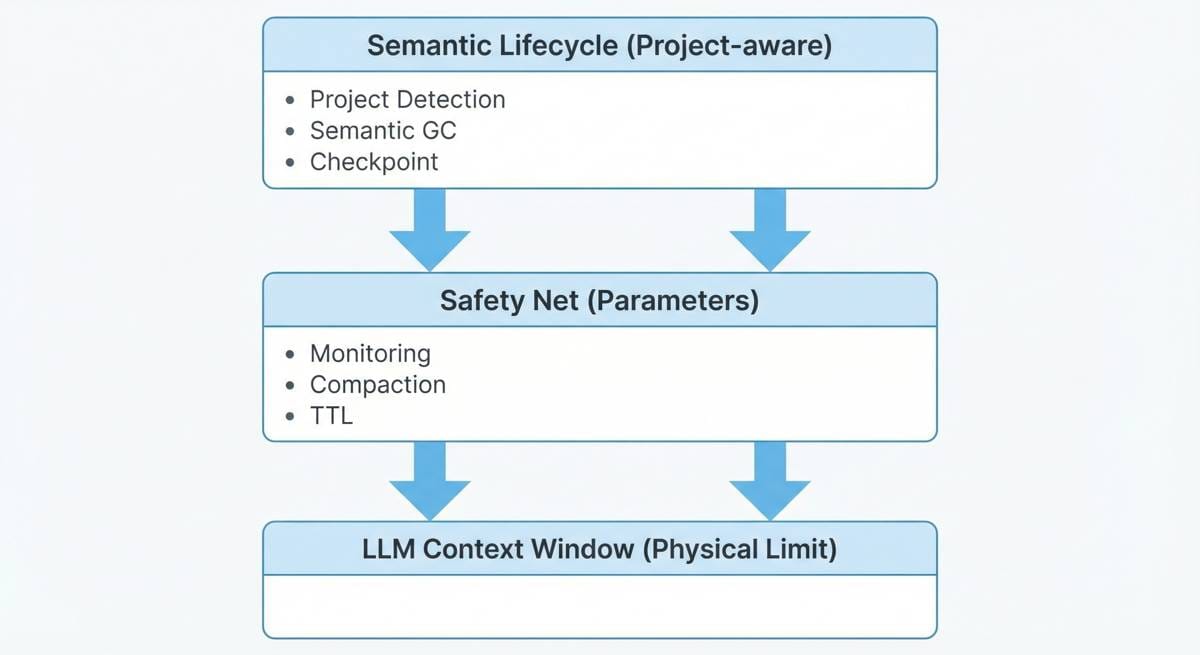
可以把它理解为一条清晰的控制栈:
- 上层:语义生命周期(项目识别、checkpoint、语义 GC)
- 中层:安全兜底(监控、压缩、TTL)
- 底层:模型的物理 Context Window
智能负责“怎么用”,参数负责“别炸”。
Checkpoint:一个系统原语,而不是功能
在 OpenClaw 中,Checkpoint 不是“存档按钮”,而是一个系统级原语。
一次 Checkpoint 会完成四个原子动作: 1. 把当前对话塌缩为结构化状态(目标 / 决策 / 下一步) 2. 将状态持久化 3. 清空当前 Context Window 4. 以最小状态重新注入系统
结果是:
Agent 在几乎零 token 占用的情况下,继续同一个长期任务。
这使得真正的 long‑running agent 成为可能。
结语:这不是省 token,而是让系统能一直跑
OpenClaw 管理 token 的目标,从来不是为了节省几分钱 API 成本。
真正的目标是:
在有限的上下文带宽内,让 Agent 可以持续运行、持续决策、持续演化。
当 token 被当成系统资源,而不是聊天副产物, 长期自治 Agent 才真正成为工程问题,而不是运气问题。
喜欢这篇文章?
🐦 点击这里一键分享到 X (Twitter)